OmniStudio DataRaptors
A DataRaptor is a mapping tool that enables you to read, transform, and write Salesforce data. There are four types of DataRaptor: Turbo Extract, Extract, Transform, and Load.
- Turbo Extract: Read data from a single Salesforce object type, with support for fields from related objects. Then select the fields to include, however, Formulas and complex field mappings aren’t supported.
- Extract: Read data from Salesforce objects and output JSON or XML with complex field mappings. Formulas are supported.
- Transform: Perform intermediate data transformations without reading from or writing to Salesforce. Formulas are supported.
- Load: Update Salesforce data from JSON or XML input. Formulas are supported.
DataRaptors typically supply data to OmniScripts, Integration Procedures, and Cards, and write updates from OmniScripts, Integration Procedures, and Cards to Salesforce. A typical data flow is as follows:
- OmniScript calls DataRaptor Extract to read data from Salesforce.
- OmniScript interacts with users to capture changes and new data.
- OmniScript calls DataRaptor Load to write data back to Salesforce.
Both Extract and Load DataRaptors can handle custom data formats. DataRaptors can access external objects and custom metadata as well as sObjects. No special syntax or additional configuration is required.
Creating your first Dataraptor
Navigate to the Omnistudio from the App launcher
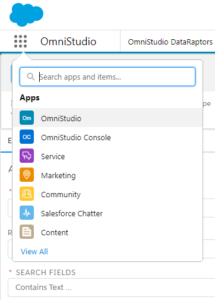
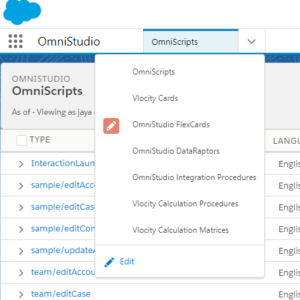
Go to the Omnistudio Dataraptors from the drop-down
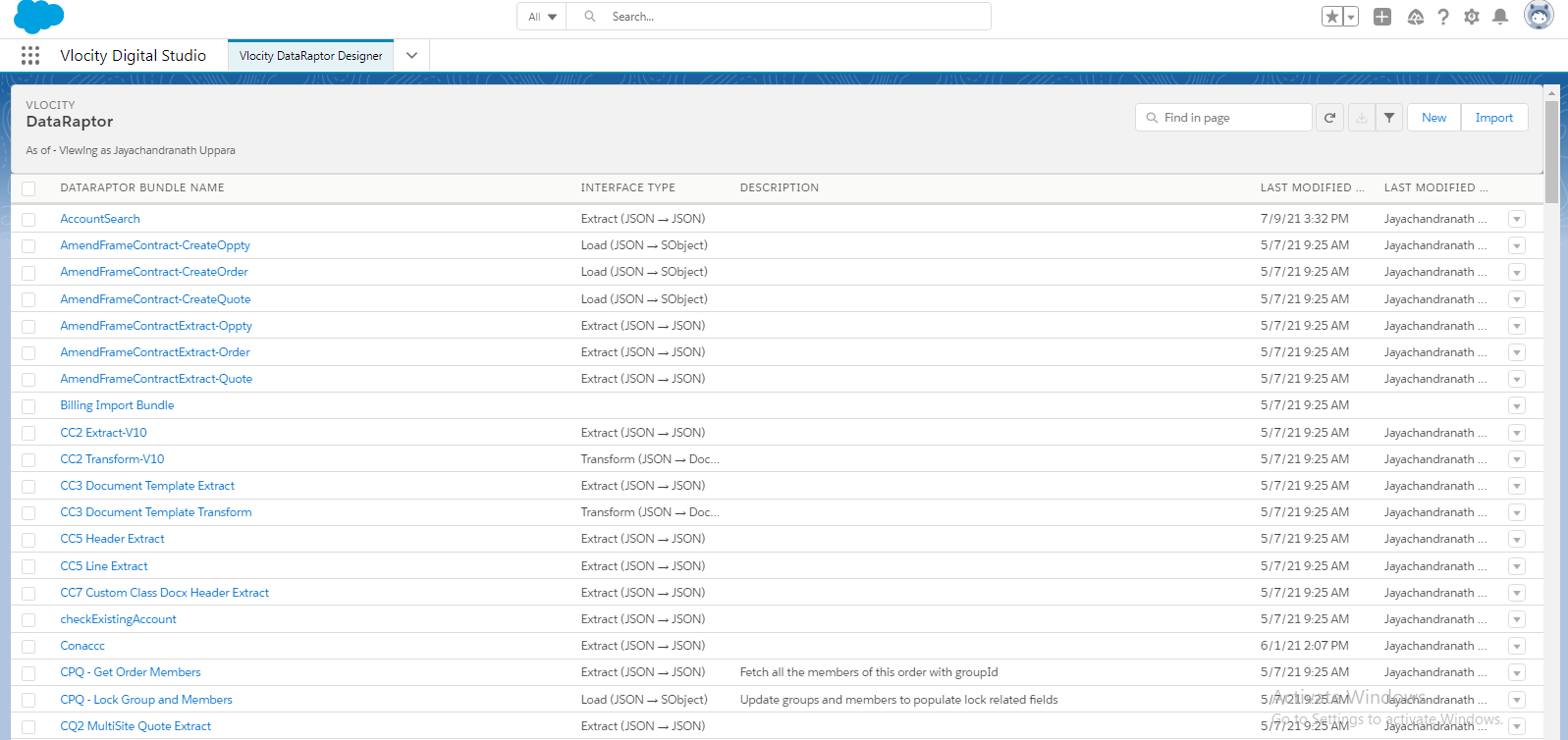
To create a new Dataraptor click “New” at the top Right Corner
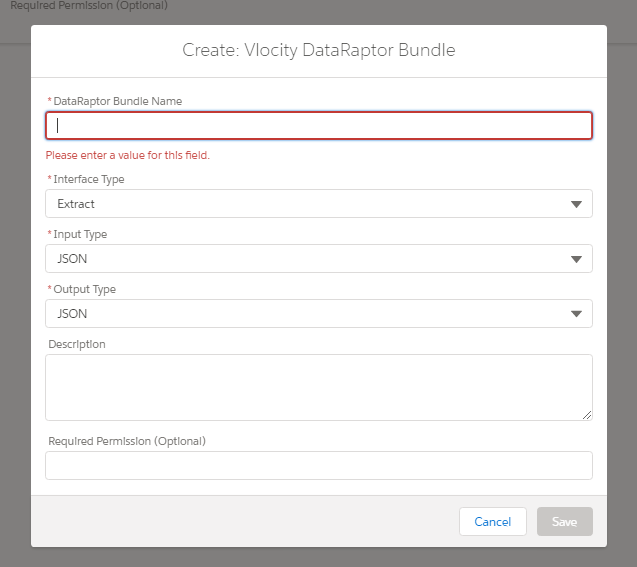
STEP #1 :
- Enter the Dataraptor Name ( Follow naming convention : Must be unique within the org, no spaces )
- Select an interface type ( Extract, Turbo Extract, Load, Transform )
- As we are creating a Extract Dataraptor
- Select Input type JSON ( Supported Input Types: JSON, XML or Custom )
- Select Output Type JSON
- Click Save
STEP #2:
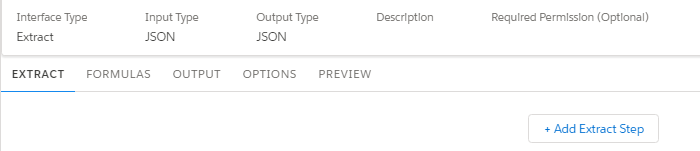
Extract Tab
In the Extract tab, specify the sObject you want the DataRaptor to query, set the filters that determine the data retrieved from the object, and specify the fields to extract.
Select an +AddExtractStep to add an object from which we need to get data
We select the Account object
Filter as Id = AccountId
- The Extract Output Path (1) specifies the top-level JSON node in the output. Because this is typically the same as the source object, select Account.
- Create a filter to determine the data to be read. A filter consists of three fields. The first field (2) refers to a field of the source object, the second field (3) is a comparison operator. The third field (4) is a quoted literal value, input parameter, or another field of the same source object. To retrieve data for the Update Account Primary Contact OmniScript example, the filter would be Id = AccountId.
Output Tab
In the Output tab, you map data from the extract step JSON to the output JSON.
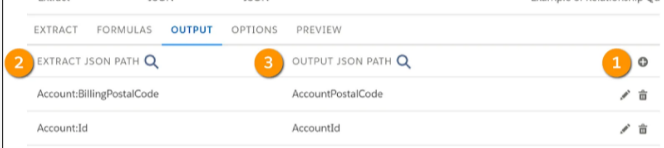
- Click the grey plus icon (1) to add an empty mapping to the list.
- In the Extract, JSON Path field (2), choose the source field from the extract step JSON.
- In the Output JSON Path field (3), specify the output path you want.
Select the fields you want to extract.
Preview Tab
You can test the input and output of the DataRaptor using the Preview tab.

Specify a Key/Value pair in the Input Parameters panel (1), such as AccountId for the Key and an account’s RecordId for the Value (2). When you execute the DataRaptor Extract, the Response pane (3) returns results to confirm it is extracting data correctly.